Enterprise chat bots can answer questions that are not common knowledge or are only known to the enterprise, such as internal documents. How do they do this?
They use a system called RAG.
TLDR
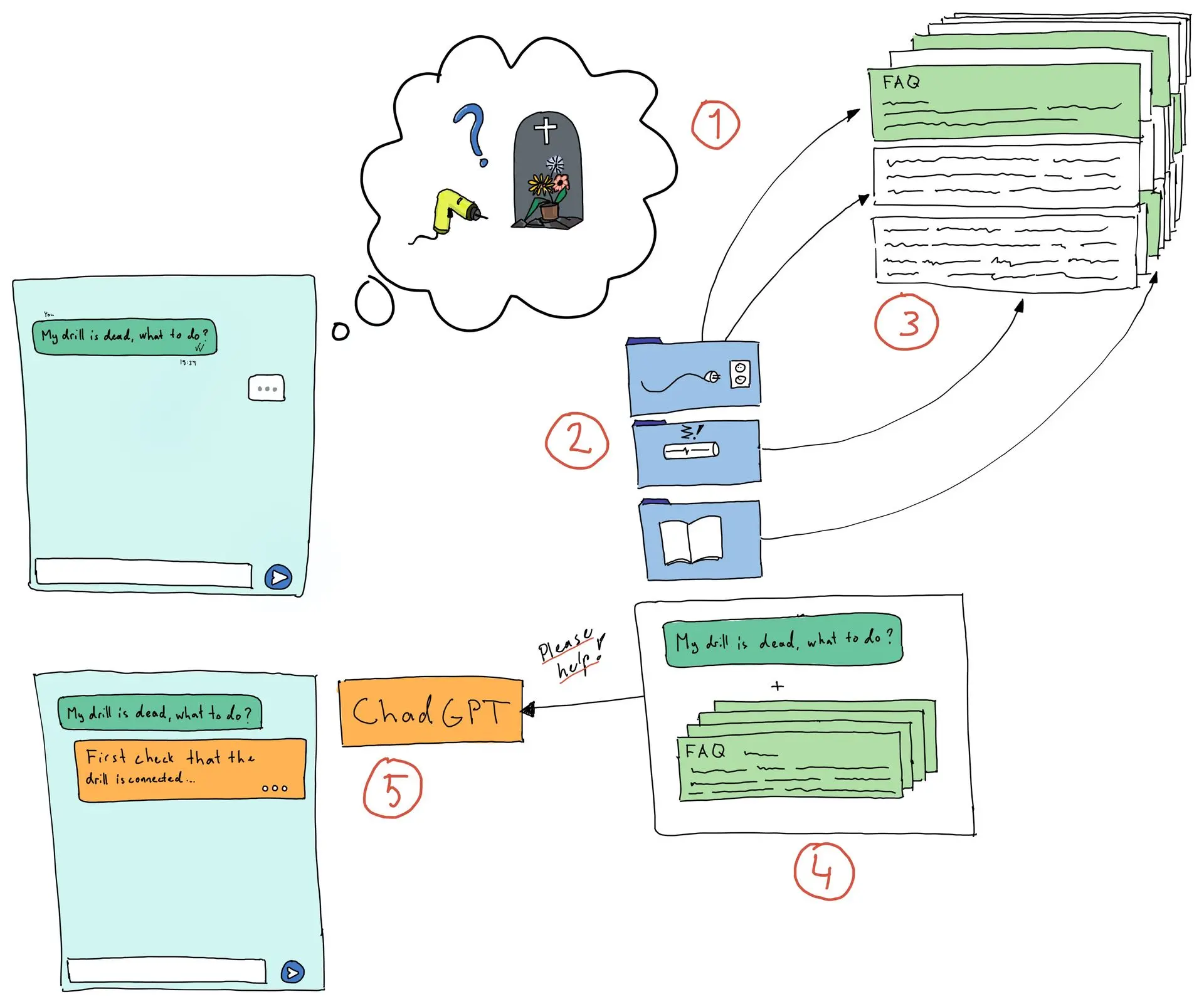
Simplified depiction of how RAG works.
If you are in a hurry, or like pictures more than reading, the above image depicts how RAG works. In short:
- Convert the input into a vector that captures its semantic meaning.
- Search the internal vector database for semantically close vectors.
- Get the original contents that created the found vectors.
- Create a prompt that combines the original question and the found content.
- Query a large language model with that prompt to generate the final answer,
What is RAG?
RAG stands for Retrieval Augmented Generation. It is a way for large language models (LLMs, e.g. ChatGPT) to answer questions based on your own information, such as internal company documents.
For example: your company has documents about the products it sells. The documents can be, for example, features, prices, installation instructions, user manuals etc. ChatGPT cannot answer questions about the products because it does not know anything about them. It might hallucinate something (make up some false information), but the answer would always be wrong.
A RAG system would find the information in the internal documents and say to the LLM: "Here is the relevant information for this question, please use this and answer the question".
We're going to use a power tool company as an example in this article, and we want to have a chat bot on our website to answer the customers' questions.
But how does it all work?
Components of RAG
Retrieval
Find relevant information from your own data.
Augmented
Add the found information to the query.
Generation
Use LLM to generate answers based on the query and the information found.
This article focuses on the retrieval and augmentation, parts of RAG. The generation, is just a LLM like ChatGPT.
Let's start with finding the relevant information.
Retrieval
A naive way to retrieve information is to use text search. However, this is not very helpful if the person asking the questions does not know exactly what to ask, or uses different terms to those used in the documents. We need to somehow "understand" the question and the content of the documents. This is called semantic search.
If the customer asks our chat bot: "My drill is dead, what to do?", we can be pretty sure that a simple text search will not find the answer in the manuals. We need to know what it means.
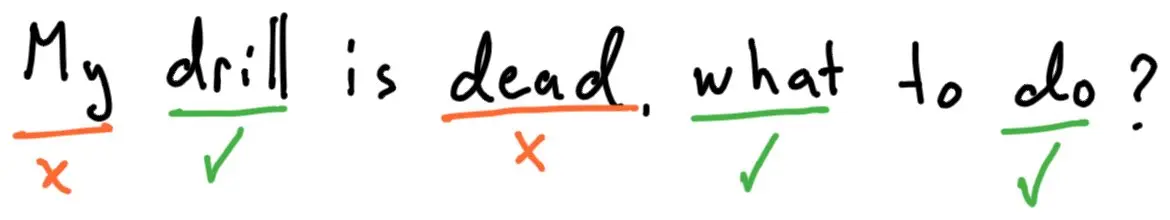
Simple text search will not find meaningful content.
Instead of using text search, we can convert the text into a format that describes the text's meaning, and search in that space instead.
That format is called embeddings. The embedding generation models are usually neural networks that convert text into a vector representation. These generated vectors are closer to each other for semantically similar pieces of text.
How the text is converted to vector embeddings is a bit complex and not in the scope of this article.
When we create our document database, we can now convert the documents into embeddings for semantic search. Usually the embeddings are generated for document chunks instead of full documents. Therefore there would be one embedding vector for each document chunk.
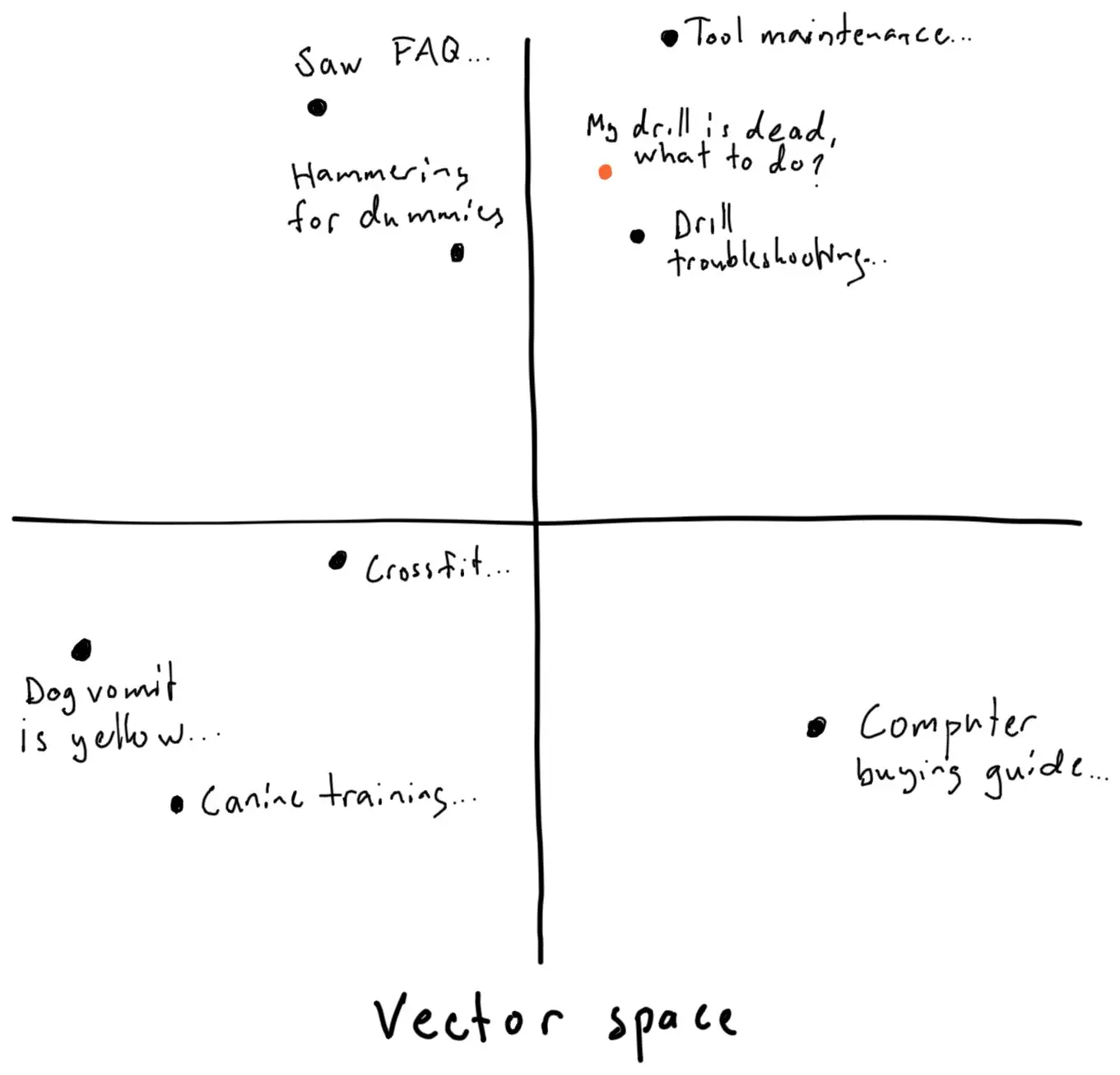
Semantically close things are close also in the vector space.
Now, when the user asks "My drill is dead, what to do?", we can convert that into an embedding vector using the same embedding model, find the nearest vectors in our vector database, and finally get the document chunks that generated those vectors. The chunks should be semantically close to the question.
In our example, we find 2 nearby vectors. The corresponding document chunks might be:
[Chunk 1]
HoleMaker2000 drill troubleshooting:
- If the drill does not turn on, check that the power cord is plugged into a wall outlet.
- If the drill still does not turn on, check that the fuse has not blown.
- If the drill bit is loose, tighten it.
- If the drill does not cut straight lines, use a saw instead."
[Chunk 2]
Watchya Finga 3500 circular saw, common problems:
- The saw can stop when fingers are between the saw blade and the wood.
- The saw will not start unless the safety switch is released.
The chunks have some semantic closeness to "drill is dead" and "what to do". In the original documents, there might also be chunks that warn about the risk of death if a tool is used incorrectly. Those chunks could also come as results in the retrieval phase but the LLM generating the final answer is usually "smart" enough to ignore that.
Augmentation
After retrieving the relevant information from the document database, we can instruct the LLM to generate a response based on that information. We augment the query. We continue with our power tool company's chat bot. The user is still waiting for an answer to their question: "My drill is dead, what to do?".
The chat bot can now first find the relevant information and ask an LLM to generate an answer in the following way.
Instructions to the LLM:
You are a helpful assistant working in a power tool company.
Your job is to answer customers' questions about power tools.
Here's what the customer wants to know:
"My drill is dead, what to do?"
Use the following documents to answer this question:
"HoleMaker2000 drill troubleshooting:
- If the drill does not turn on, check that the power cord is plugged into a wall outlet.
- If the drill still does not turn on, check that the fuse has not blown.
- If the drill bit is loose, tighten it.
- If the drill does not cut straight lines, use a saw instead."
"Watchya Finga 3500 circular saw, common problems:
- The saw can stop when fingers are between the saw blade and the wood.
- The saw will not start unless the safety switch is released."
Now the LLM has all the information it needs to give the customer a proper answer:
You should first check that the drill is plugged into a wall outlet. If that does not work, check that the fuse is intact.
If everything looks fine and the drill still does not start, it is likely that the drill is broken and needs to be repaired by an authorized service center.
The customer is happy and business is thriving.
But why don't they often work?
In our simple example the semantic search was able to find the relevant information. That is not always the case. There might be thousands of documents to search and the chunks may not always contain all the information that is relevant to the question.
How the chunks are created, i.e. how the original documents are split into smaller pieces, is somewhat arbitrary. It can be done in several ways. One way is to split by headings.
However, for a single paragraph to be meaningful, it often needs the context of other paragraphs and sections in the document. That could be added in the chunks as metadata, right?
Yes. The question is: what to add? Document title? Nearby headings? Keywords? Other semantics? But weren't we creating a semantic search in the first place?
You could increase the chunk size, but that comes at a cost. The whole chunk is converted into a single vector. What information can that vector capture if the chunk contains multiple topics and ideas? Maybe a larger vector? Slower and more expensive.
You could also include more chunks in the augmentation phase. But that might not fit into the LLM's memory, the context window. Alternatively, the costs of the LLM would skyrocket since every character incurs a cost.
Companies often want to limit risks. What if the LLM hallucinates? That could happen if the semantic search does not return any good content and the LLM tries to generate an answer no matter what. It does not really understand what it's doing.
These are only some examples, there's more.
So maybe just return some generic answer and a link to the original documents? Safe. Nobody will sue the company.
And that's how you get enterprise chat bots that are infuriating and make you want to switch your bank, airline and insurance company.
